Turning Field Analysis Data into AI Workflows
How field measurements, geospatial context, and production feedback can become reliable AI workflows instead of isolated reports.
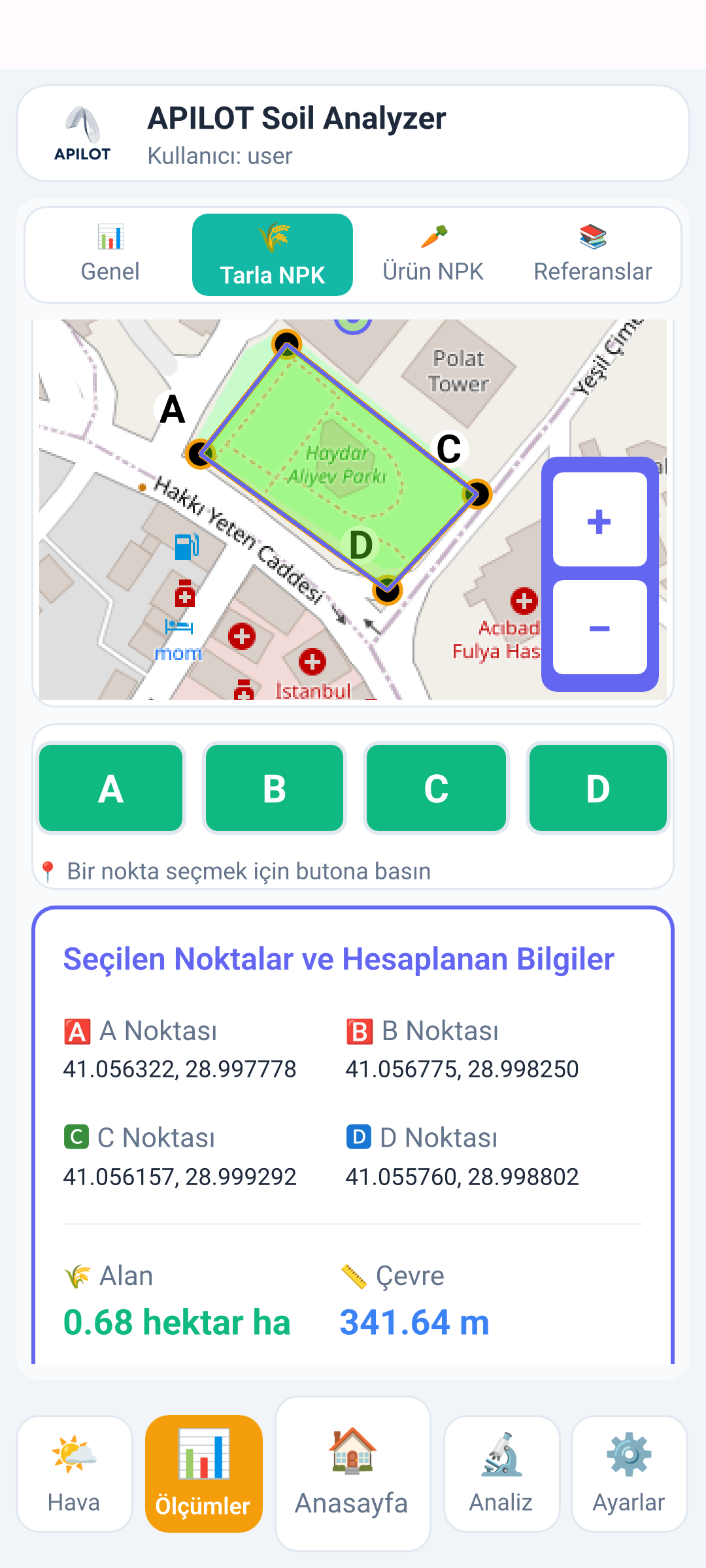
Field analysis becomes useful when it moves beyond a one-time report. Coordinates, selected points, area calculations and soil values can feed an AI workflow that helps teams compare zones, recommend next actions and learn from future outcomes.
Start with trustworthy field data
AI quality depends on measurement quality. A field workflow should preserve where each reading came from, which boundary it belongs to, when it was captured, and what conditions influenced the result. Without that context, a model can produce confident but weak recommendations.
Workflow building blocks
- Geospatial context: connect measurements to selected field points and calculated area.
- Data normalization: clean units, ranges and missing values before analysis.
- Model feedback: compare AI suggestions with actual field outcomes over time.
- Operator interface: show recommendations in language the field team can act on.
Production AI is a loop
The most important part is the loop: collect data, analyze, recommend, act, and measure the result. LexpAI designs these loops so teams can trace why a recommendation was made and improve it with every new field cycle.
Where LexpAI helps
We connect mobile data capture, cloud storage, analytics and AI automation into practical workflows. That means field teams get usable insight, managers get structured history, and the product keeps learning from real operations instead of isolated spreadsheets.
Deploying machine learning models in production is significantly different from developing them in research environments. Production ML systems require robust infrastructure, comprehensive monitoring, automated retraining pipelines, and careful consideration of business requirements. This guide covers the essential aspects of implementing ML in production systems.
The Production ML Challenge
While 87% of data science projects never make it to production, those that do face unique challenges. Production ML systems must handle real-world data, maintain performance over time, and integrate seamlessly with existing business processes.
Key Challenges:
- Data Drift: Model performance degrades as real-world data changes
- Scalability: Systems must handle varying load and data volumes
- Monitoring: Continuous tracking of model performance and system health
- Versioning: Managing model versions and rollbacks
- Integration: Seamless integration with existing business systems
MLOps: The Foundation
What is MLOps?
MLOps (Machine Learning Operations) is the practice of applying DevOps principles to machine learning systems. It encompasses the entire ML lifecycle from development to deployment and maintenance.
Core MLOps Principles:
- Automation: Automated training, testing, and deployment pipelines
- Versioning: Version control for code, data, and models
- Monitoring: Continuous monitoring of model performance
- Reproducibility: Consistent results across environments
- Collaboration: Effective teamwork between data scientists and engineers
Production ML Architecture
1. Data Pipeline
A robust data pipeline is the foundation of any production ML system. It should handle data ingestion, validation, preprocessing, and storage.
# Example data pipeline with Apache Airflow
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime, timedelta
def extract_data():
"""Extract data from various sources"""
# Implementation for data extraction
pass
def validate_data():
"""Validate data quality and schema"""
# Implementation for data validation
pass
def preprocess_data():
"""Preprocess data for model training"""
# Implementation for data preprocessing
pass
# Define DAG
dag = DAG(
'ml_data_pipeline',
start_date=datetime(2025, 1, 1),
schedule_interval=timedelta(hours=1)
)
extract_task = PythonOperator(
task_id='extract_data',
python_callable=extract_data,
dag=dag
)
validate_task = PythonOperator(
task_id='validate_data',
python_callable=validate_data,
dag=dag
)
preprocess_task = PythonOperator(
task_id='preprocess_data',
python_callable=preprocess_data,
dag=dag
)
extract_task >> validate_task >> preprocess_task2. Model Training Pipeline
Automated model training pipelines ensure consistent model development and deployment.
# Example MLflow training pipeline
import mlflow
import mlflow.sklearn
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
import pandas as pd
def train_model():
# Load and prepare data
data = pd.read_csv('data/processed/training_data.csv')
X = data.drop('target', axis=1)
y = data['target']
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Start MLflow run
with mlflow.start_run():
# Train model
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Evaluate model
train_score = model.score(X_train, y_train)
test_score = model.score(X_test, y_test)
# Log metrics
mlflow.log_metric("train_accuracy", train_score)
mlflow.log_metric("test_accuracy", test_score)
# Log model
mlflow.sklearn.log_model(model, "model")
# Log parameters
mlflow.log_params(model.get_params())
return model, test_score
if __name__ == "__main__":
model, score = train_model()
print(f"Model accuracy: {score:.4f}")3. Model Serving Infrastructure
Model serving infrastructure must be scalable, reliable, and performant. Common approaches include:
- REST APIs: Simple HTTP endpoints for model inference
- gRPC: High-performance RPC for low-latency inference
- Batch Processing: For large-scale predictions
- Real-time Streaming: For real-time predictions
# Example FastAPI model serving
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import joblib
import numpy as np
app = FastAPI()
# Load model
model = joblib.load('models/production_model.pkl')
class PredictionRequest(BaseModel):
features: list[float]
class PredictionResponse(BaseModel):
prediction: float
confidence: float
@app.post("/predict", response_model=PredictionResponse)
async def predict(request: PredictionRequest):
try:
# Make prediction
features = np.array(request.features).reshape(1, -1)
prediction = model.predict(features)[0]
confidence = model.predict_proba(features).max()
return PredictionResponse(
prediction=float(prediction),
confidence=float(confidence)
)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.get("/health")
async def health_check():
return {"status": "healthy"}Model Monitoring and Observability
1. Performance Monitoring
Continuous monitoring of model performance is crucial for detecting degradation and ensuring business value.
# Example monitoring with Prometheus
from prometheus_client import Counter, Histogram, Gauge
import time
# Define metrics
prediction_counter = Counter('model_predictions_total', 'Total predictions made')
prediction_latency = Histogram('model_prediction_duration_seconds', 'Prediction latency')
model_accuracy = Gauge('model_accuracy', 'Current model accuracy')
def monitored_predict(model, features):
start_time = time.time()
try:
prediction = model.predict(features)
prediction_counter.inc()
# Update accuracy if ground truth is available
# model_accuracy.set(calculate_accuracy(predictions, ground_truth))
return prediction
finally:
prediction_latency.observe(time.time() - start_time)2. Data Drift Detection
Data drift occurs when the distribution of input data changes over time, leading to degraded model performance.
# Example drift detection
import numpy as np
from scipy import stats
def detect_data_drift(reference_data, current_data, threshold=0.05):
"""
Detect data drift using Kolmogorov-Smirnov test
"""
drift_detected = {}
for column in reference_data.columns:
if reference_data[column].dtype in ['float64', 'int64']:
# Perform KS test
ks_statistic, p_value = stats.ks_2samp(
reference_data[column].dropna(),
current_data[column].dropna()
)
drift_detected[column] = p_value < threshold
return drift_detected
# Usage
reference_data = pd.read_csv('data/reference_distribution.csv')
current_data = get_current_data()
drift_results = detect_data_drift(reference_data, current_data)
print("Drift detected in columns:", [col for col, drifted in drift_results.items() if drifted])3. Model Explainability
Model explainability is crucial for building trust and understanding model decisions.
# Example SHAP explainability
import shap
def explain_prediction(model, features, feature_names):
"""
Generate SHAP explanations for model predictions
"""
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(features)
# Create explanation plot
shap.summary_plot(shap_values, features, feature_names=feature_names)
return shap_values
# Usage
feature_names = ['feature1', 'feature2', 'feature3']
explanation = explain_prediction(model, X_sample, feature_names)Automated Retraining and Deployment
1. Continuous Training Pipeline
Automated retraining ensures models stay current with changing data patterns.
# Example GitHub Actions workflow for retraining
name: ML Model Retraining
on:
schedule:
- cron: '0 2 * * *' # Daily at 2 AM
workflow_dispatch: # Manual trigger
jobs:
retrain:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: '3.9'
- name: Install dependencies
run: |
pip install -r requirements.txt
- name: Run training pipeline
run: |
python train_model.py
- name: Evaluate model
run: |
python evaluate_model.py
- name: Deploy if improved
run: |
python deploy_model.py
if: steps.evaluate.outputs.improved == 'true'2. A/B Testing Framework
A/B testing allows safe deployment of new models by comparing them with existing ones.
# Example A/B testing framework
import random
from typing import Dict, Any
class ABTestManager:
def __init__(self, traffic_split: float = 0.1):
self.traffic_split = traffic_split
self.models = {}
self.metrics = {}
def register_model(self, model_id: str, model: Any):
"""Register a new model for A/B testing"""
self.models[model_id] = model
self.metrics[model_id] = {
'predictions': 0,
'correct_predictions': 0,
'avg_latency': 0
}
def get_model(self, user_id: str) -> str:
"""Get model ID for user based on traffic split"""
if random.random() < self.traffic_split:
return 'new_model'
return 'baseline_model'
def record_prediction(self, model_id: str, prediction: Any,
ground_truth: Any = None, latency: float = 0):
"""Record prediction metrics"""
self.metrics[model_id]['predictions'] += 1
self.metrics[model_id]['avg_latency'] = (
(self.metrics[model_id]['avg_latency'] *
(self.metrics[model_id]['predictions'] - 1) + latency) /
self.metrics[model_id]['predictions']
if ground_truth is not None:
if prediction == ground_truth:
self.metrics[model_id]['correct_predictions'] += 1
def get_model_performance(self, model_id: str) -> Dict[str, float]:
"""Get performance metrics for a model"""
metrics = self.metrics[model_id]
accuracy = (metrics['correct_predictions'] /
metrics['predictions'] if metrics['predictions'] > 0 else 0)
return {
'accuracy': accuracy,
'total_predictions': metrics['predictions'],
'avg_latency': metrics['avg_latency']
}Security and Compliance
1. Model Security
ML models can be vulnerable to various attacks, including adversarial examples and model inversion.
- Input Validation: Validate all inputs to prevent adversarial attacks
- Model Encryption: Encrypt models to prevent theft
- Access Control: Implement proper authentication and authorization
- Audit Logging: Log all model interactions for security analysis
2. Privacy and Compliance
ML systems must comply with privacy regulations like GDPR and industry-specific requirements.
# Example data anonymization
import hashlib
import pandas as pd
def anonymize_data(data: pd.DataFrame, sensitive_columns: list) -> pd.DataFrame:
"""
Anonymize sensitive data using hashing
"""
anonymized_data = data.copy()
for column in sensitive_columns:
if column in anonymized_data.columns:
# Hash sensitive data
anonymized_data[column] = anonymized_data[column].astype(str).apply(
lambda x: hashlib.sha256(x.encode()).hexdigest()[:16]
)
return anonymized_data
# Usage
sensitive_columns = ['email', 'phone', 'ssn']
anonymized_df = anonymize_data(user_data, sensitive_columns)Best Practices for Production ML
1. Infrastructure as Code
- Use Terraform or CloudFormation for infrastructure management
- Implement containerization with Docker
- Use Kubernetes for orchestration
- Implement CI/CD pipelines
2. Testing Strategy
- Unit tests for individual components
- Integration tests for data pipelines
- Model validation tests
- Load testing for serving infrastructure
3. Documentation
- Comprehensive API documentation
- Model cards with performance characteristics
- Runbooks for common issues
- Architecture diagrams
Conclusion
Implementing machine learning in production requires careful consideration of infrastructure, monitoring, security, and operational processes. By following MLOps best practices and building robust systems from the start, organizations can successfully deploy and maintain ML models that deliver real business value.
The key to success is treating ML systems as production software, with all the rigor and discipline that entails. This includes proper testing, monitoring, documentation, and operational procedures.